前言
大多数人用 Git 只停留在 add commit push pull 四板斧。代码能交上去,但出了问题不知道怎么查,协作起来没有规范。
本文从基础概念讲起,说清楚 Git 到底在干什么;然后给出一套可以直接用的团队协作规范;最后聊一些能提升效率的冷门技巧。
一、Git 是做什么的
版本控制解决什么问题
想象一下你写论文的过程:
- 第一版、第二版、第三版、定稿版、最终版、最终版2……
- 改了半天想找回昨天写的版本,但早就覆盖了
- 和同学合作写文档,互相发压缩包,最后分不清谁的是最新的
版本控制系统就是来解决这些问题的。你只需要记住三个要点:
- 记录历史 — 每一次修改都会被记录下来,随时可以回头看或者回退
- 多人协作 — 每个人改各自的,最后合并到一起
- 分支并行 — 可以同时在多个方向开发,互不干扰
Git 的特点
Git 是目前使用最广泛的版本控制系统,由 Linux 之父 Linus Torvalds 于 2005 年创建。它的核心特点是分布式——每个本地仓库都有完整的历史记录,离线也能提交,服务器挂了也能恢复。
与之对比的是集中式系统(SVN、CVS),所有历史都存放在中央服务器,服务器一挂就全丢,网络断了就没法干活。
数据的三种状态
理解 Git 最关键的是知道文件在 Git 中会处于三种状态:
| 状态 | 含义 | 所在位置 |
|---|---|---|
| 已修改 (modified) | 改了文件,但还没保存到 Git | 工作区 |
| 已暂存 (staged) | 把修改标记为”待提交” | 暂存区 |
| 已提交 (committed) | 修改已保存到 Git 仓库 | 本地仓库 |
这三个状态对应 Git 的三个区域:
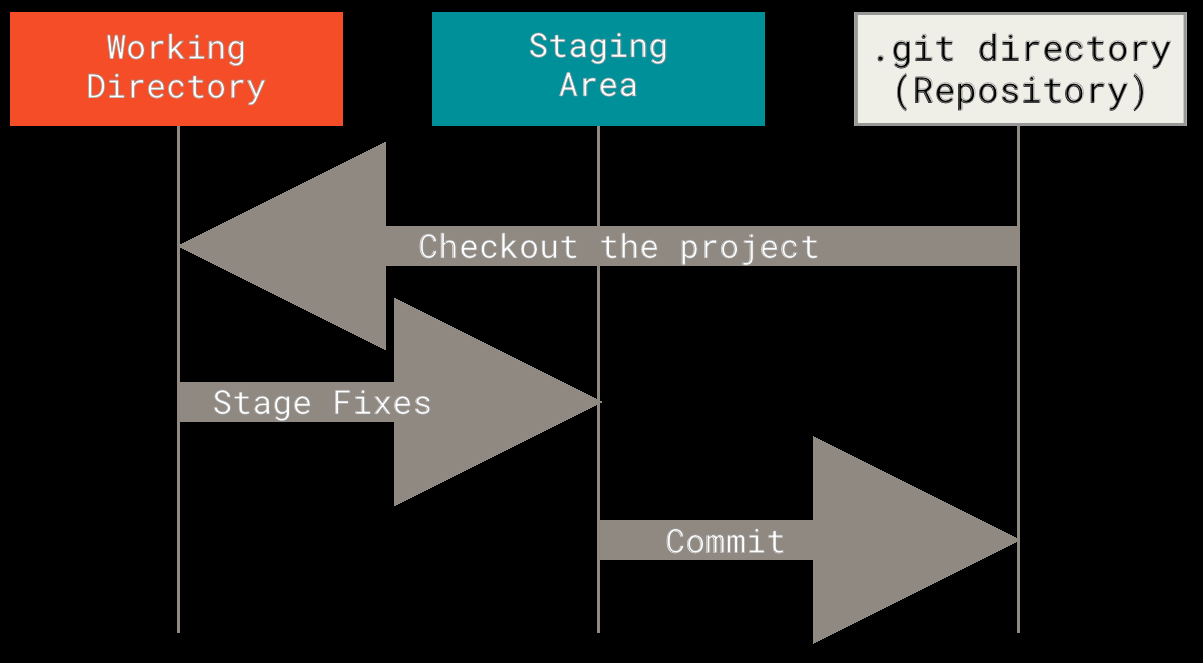
文件在三个区域之间的流转,就是 Git 最基本的操作。
二、Git 基础工作流
核心命令一览
下面这张表概括了最常用的 Git 命令,以及它们把数据从哪送到哪:
| 命令 | 作用 | 数据流向 |
|---|---|---|
git status |
查看当前文件的所处状态 | — |
git add <file> |
将修改存入暂存区 | 工作区 → 暂存区 |
git commit -m "msg" |
将暂存区的内容提交成 commit | 暂存区 → 本地仓库 |
git push |
将本地提交推送到远程 | 本地仓库 → 远程仓库 |
git pull |
从远程拉取最新代码 | 远程仓库 → 工作区 |
git log |
查看提交历史 | — |
git diff |
查看具体改了什么内容 | — |
文件的状态转换
在 Git 中,一个文件可能处于以下状态之一:
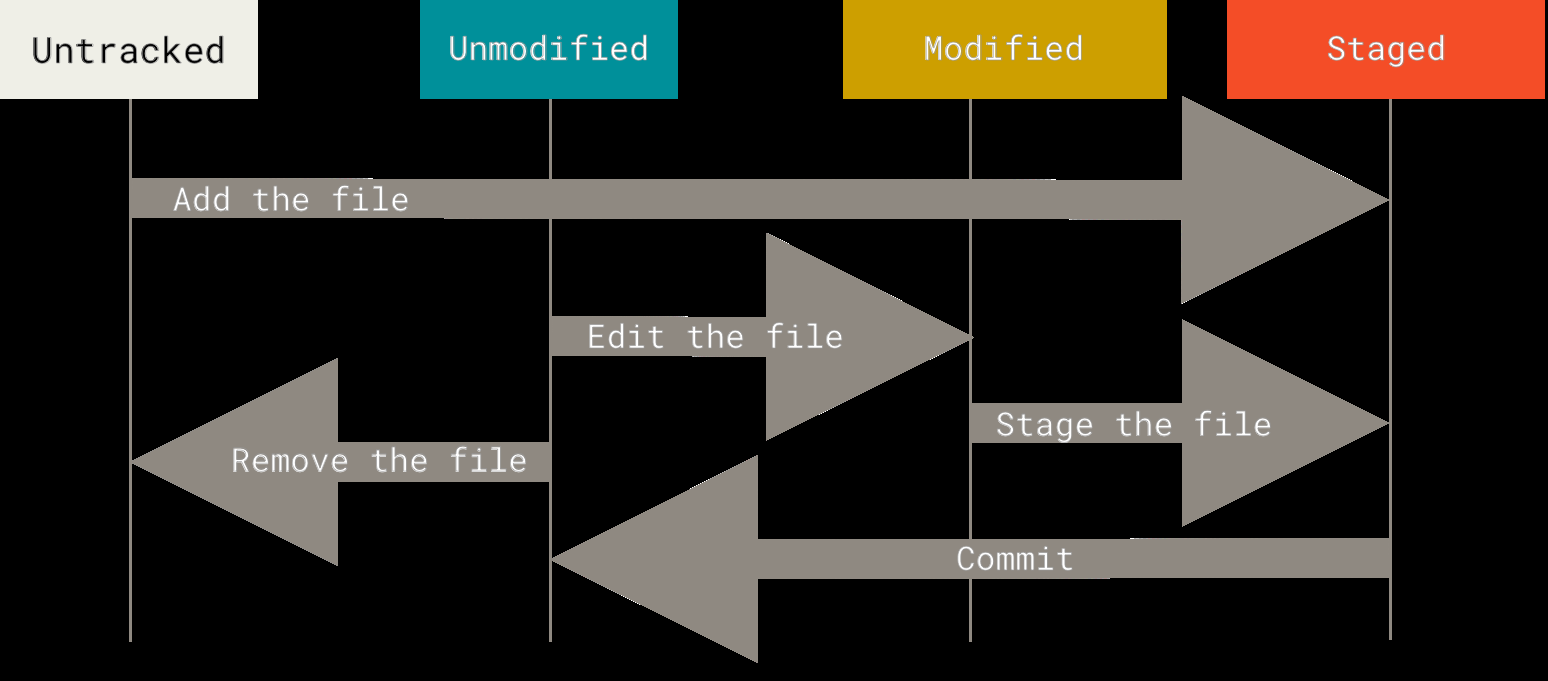
也就是说:
- 新建的文件(Untracked)→
git add→ 暂存(Staged) - 已跟踪的文件修改后(Modified)→
git add→ 暂存(Staged) - 暂存区的内容(Staged)→
git commit→ 成为一次 commit
一个完整的示例
从头到尾走一遍最基本的流程:
1 | # 初始化仓库或克隆已有的 |
.gitignore:不该提交的文件
项目中总有不想被 Git 跟踪的文件(编译产物、依赖包、系统文件)。在项目根目录创建一个 .gitignore 文件,Git 会自动忽略它们:
1 | # 编译输出 |
1 | # 全局 gitignore(对所有项目生效) |
注意:
.gitignore只对尚未被跟踪的文件有效。如果文件已经被git add过,再添加 ignore 规则不会生效——需要用git rm --cached先取消跟踪。
查看修改内容
git status 告诉你”改了什么文件”,git diff 告诉你”具体改了哪些行”:
1 | # 查看工作区与暂存区的差异(还没 add 的修改) |
查看提交详情:git show / git shortlog
1 | # 查看最新 commit 的详细内容(diff + metadata) |
文件操作:git rm / git mv
1 | # 删除文件并自动暂存(git add + rm 一步完成) |
提交详解:git commit
1 | # 最基本的用法(会打开编辑器让你写 message) |
何时用 -a: 只对已经被 Git 跟踪的文件有效。新建的文件(Untracked)仍需先 git add。
何时用 --amend: 在上一次 commit 还没有推送时,修改它的 message 或补充漏掉的文件。先把漏掉的文件 git add 到暂存区,再 git commit --amend。
撤销与回退
操作中难免犯错,Git 提供了多种撤销方式,覆盖不同场景:
场景一:暂存区 → 工作区(取消暂存)
已经 git add 了,但突然不想把这个文件包含在这次 commit 里:
1 | # 把文件从暂存区移回工作区,修改内容保留 |
场景二:工作区 → 丢弃修改
改到一半发现改错了,想放弃对某个文件的修改,回到上一次 commit 的状态:
1 | # 丢弃工作区的修改(不可恢复!谨慎操作) |
场景三:本地仓库 → 暂存区(撤回 commit 保留修改)
commit 完了发现漏了文件或 message 写错了,想撤销这次 commit 但保留改动:
1 | # 撤销最近一次 commit,改动回到暂存区 |
场景四:本地仓库 → 工作区(撤回 commit 取消暂存)
想完全撤销上一次 commit,所有改动回到工作区(未暂存状态):
1 | # 撤销最近一次 commit,改动回到工作区 |
场景五:本地仓库 → 彻底抹掉
不想要这次提交了,连同改动一起扔掉:
1 | # 警告:会丢失所有未提交的工作! |
以上所有操作只针对本地历史。如果 commit 已经推送到了远程,请用
git revert。
各命令的影响范围一览:
| 操作 | commit | 暂存区 | 工作区 | 适合场景 |
|---|---|---|---|---|
git restore --staged |
— | 重置 | 保留 | 取消暂存 |
git restore <file> |
— | — | 重置 | 丢弃工作区修改 |
git reset --soft HEAD~1 |
撤回 | 保留 | 保留 | 撤回 commit 保留改动 |
git reset HEAD~1 |
撤回 | 重置 | 保留 | 撤回 commit 取消暂存 |
git reset --hard HEAD~1 |
撤回 | 重置 | 重置 | 彻底丢弃 |
git switch / git restore:新版命令
Git 2.23 之后,原来 git checkout 的功能被拆分成两个更清晰的命令:
1 | # 切换分支(替代 git checkout <branch>) |
两者分工明确:switch 只管分支切换,restore 只管文件恢复。
标签:git tag
标签(tag)用于给某个特定的 commit 打上标记,通常用于版本发布(如 v1.0、v2.0.1)。
1 | # 给当前 commit 打标签 |
Git 配置:本地与远程
配置层级
Git 的配置分为三个层级,优先级从高到低:
| 层级 | 命令 | 配置文件位置 | 生效范围 |
|---|---|---|---|
| local | git config(无选项) |
.git/config |
当前仓库 |
| global | git config --global |
~/.gitconfig |
当前用户的所有仓库 |
| system | git config --system |
/etc/gitconfig |
整台机器的所有用户 |
查找配置值时,Git 会从 local → global → system 逐层查找,最先找到的值胜出。
1 | # 查看所有配置及来源 |
远程仓库管理

一个本地仓库可以关联多个远程仓库。git clone 会自动添加一个名为 origin 的远程:
1 | # 查看所有远程仓库 |
远程交互
1 | # 从远程拉取但不合并(fetch = 下载到本地,不自动合并) |
fetch vs pull 的区别: git fetch 只把远程的数据下载到本地数据库,不改变你当前的工作目录。你需要手动 git merge 来合并。git pull 是 fetch 完直接自动合并——方便但可能引入意外的合并提交。
三、项目规范:PR 与 Review 流程
一个人开发怎么折腾都行,但团队协作必须有一套统一规范。
3.1 分支规范
推荐的分支模型(简化版 Git Flow):
| 分支 | 用途 |
|---|---|
main |
生产就绪,只合不入 |
dev |
日常开发集成 |
feat/xxx |
功能分支,从 dev 切出 |
fix/xxx |
修复分支 |
release/x.x |
发布前准备 |
原则: main 只接受 PR,不允许直接 push。每个 PR 必须经过 review。
要理解分支,先要知道 Git 是怎么存数据的。
Git 怎么存数据:snapshot 而非差异
很多版本控制系统(如 SVN)存储的是文件差异——每个版本只记录”这一行改了、那一行删了”。Git 的做法完全不同:每次提交都存储一个完整的目录快照。
当你 git commit 时,Git 内部会创建三层对象:
- Blob — 保存每个文件的内容(相当于文件内容的快照)
- Tree — 保存目录结构,记录每个文件名对应哪个 blob(或子 tree)
- Commit — 指向一棵 tree,还记录了作者、时间、提交信息、父 commit
假如你在一个有三个文件的目录中执行 git add 和 git commit,仓库里会形成这样的结构:

每个 commit 都通过 tree 记录了那一刻的完整目录状态,commit 之间通过 parent 指针串联成历史。
分支是什么
分支本质上就是一个指向 commit 的可移动指针。
Git 的默认分支名是 master(现在很多项目改叫 main)。每次提交,当前分支的指针就自动向前移动:

创建分支
创建新分支就是创建一个新的指针,指向你当前所在的 commit:
1 | git branch testing |
执行后两个分支指向同一个 commit:
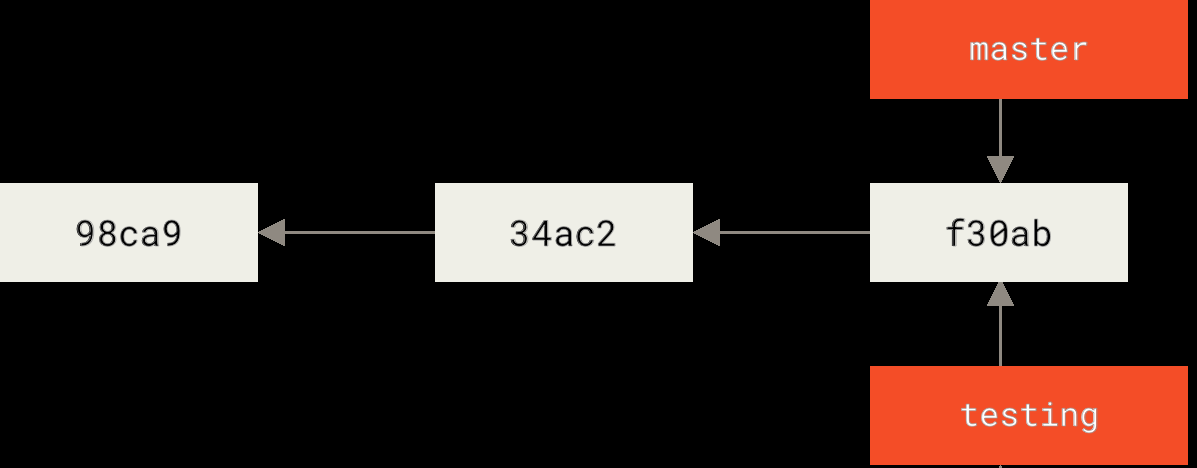
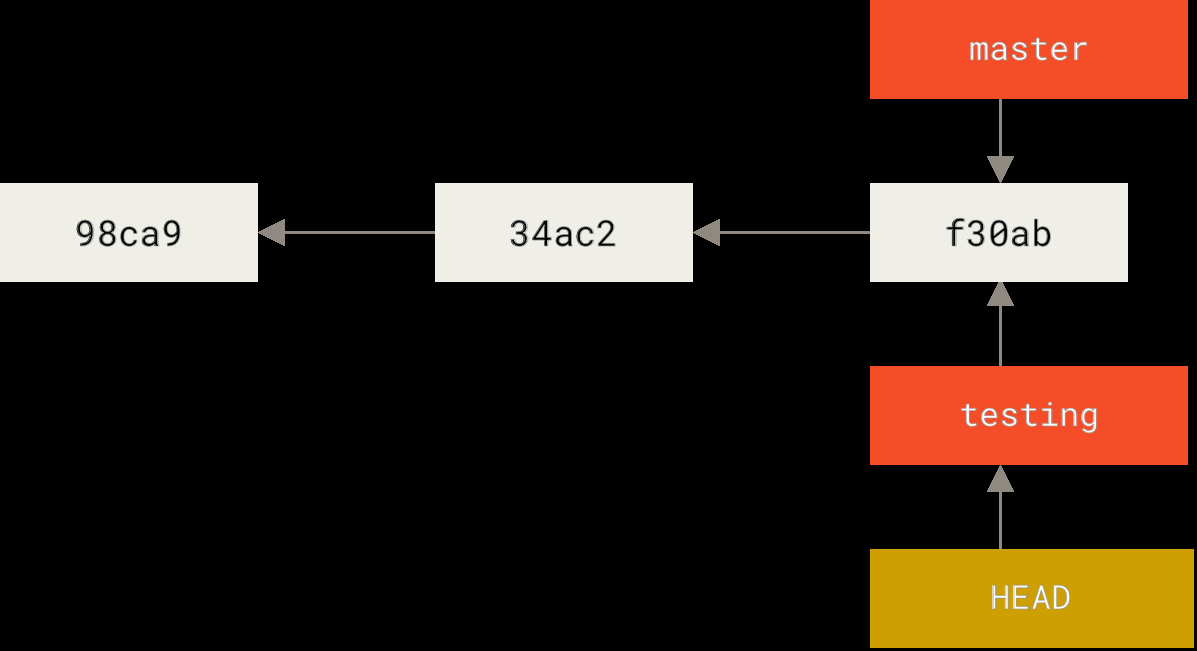
那 Git 怎么知道当前在哪个分支上?它用一个特殊指针 HEAD 来标记。
HEAD:当前在哪
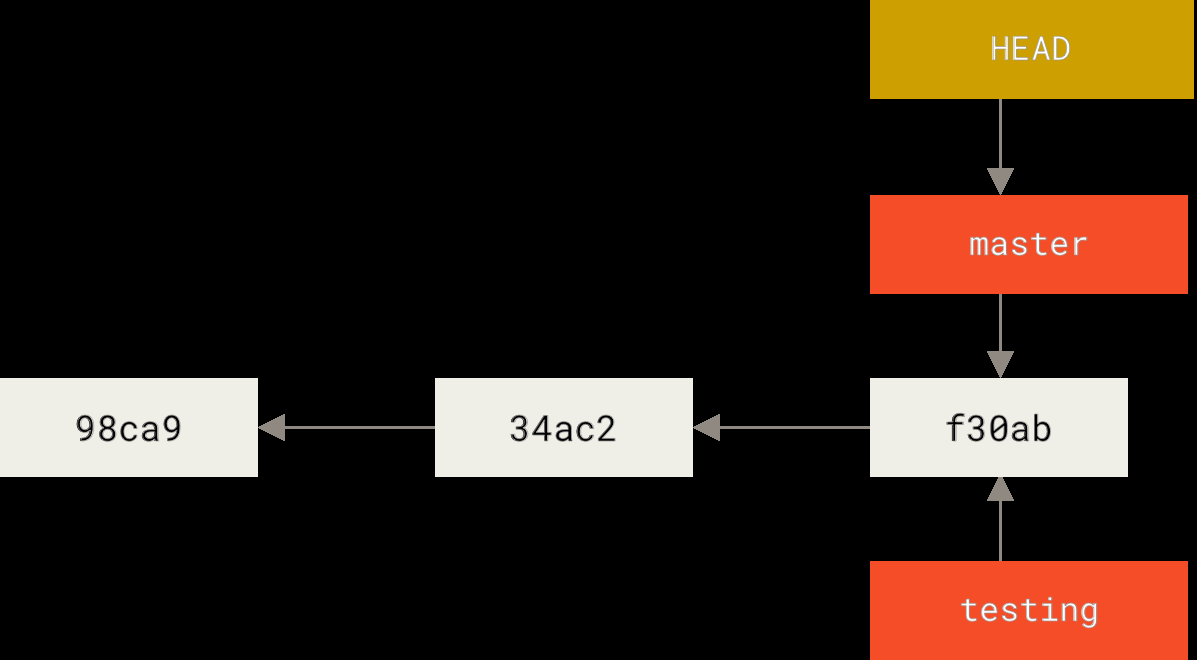
git branch 只创建分支,不会自动切换。要切换分支需要:
1 | git checkout testing |
这会移动 HEAD 让它指向 testing 分支:
在分支上提交
现在在 testing 上做一次提交:
1 | vim test.rb |
提交后 testing 指针向前移动,而 master 还停留在原地:

切回 master 看看:
1 | git checkout master |
切换分支时 Git 会自动还原工作目录里的文件,让它们回到 master 指向的那个 snapshot。这意味着你在 testing 上的工作会被”收起来”,master 目录干干净净。

然后在 master 上也做一次提交。现在两个分支从同一个起点分道扬镳——这就是分叉:

用 git log --oneline --decorate --graph --all 可以清晰地看到分叉:
1 | * c2b9e (HEAD, master) Make other changes |
分支在 Git 里只是一个 41 字节的文件(40 位 SHA-1 + 换行符),创建和销毁几乎零成本。这跟 SVN 等老式 VCS 完全不同——那些系统需要复制整个项目目录才能创建分支。
合并分支
场景一:快进合并(Fast-Forward)
假设在 master 上遇到了一个紧急 bug,需要立即修复。先创建一个 hotfix 分支:
1 | git checkout -b hotfix |
修复完成后切回 master 合并:
1 | git checkout master |
因为 hotfix 的 commit 直接排在 master 的后面(线性关系),Git 不需要做实际合并,只需要把 master 指针向前移动到 hotfix 的位置——这叫做快进合并:

修复上线后,hotfix 分支没用了,删掉:
1 | git branch -d hotfix |
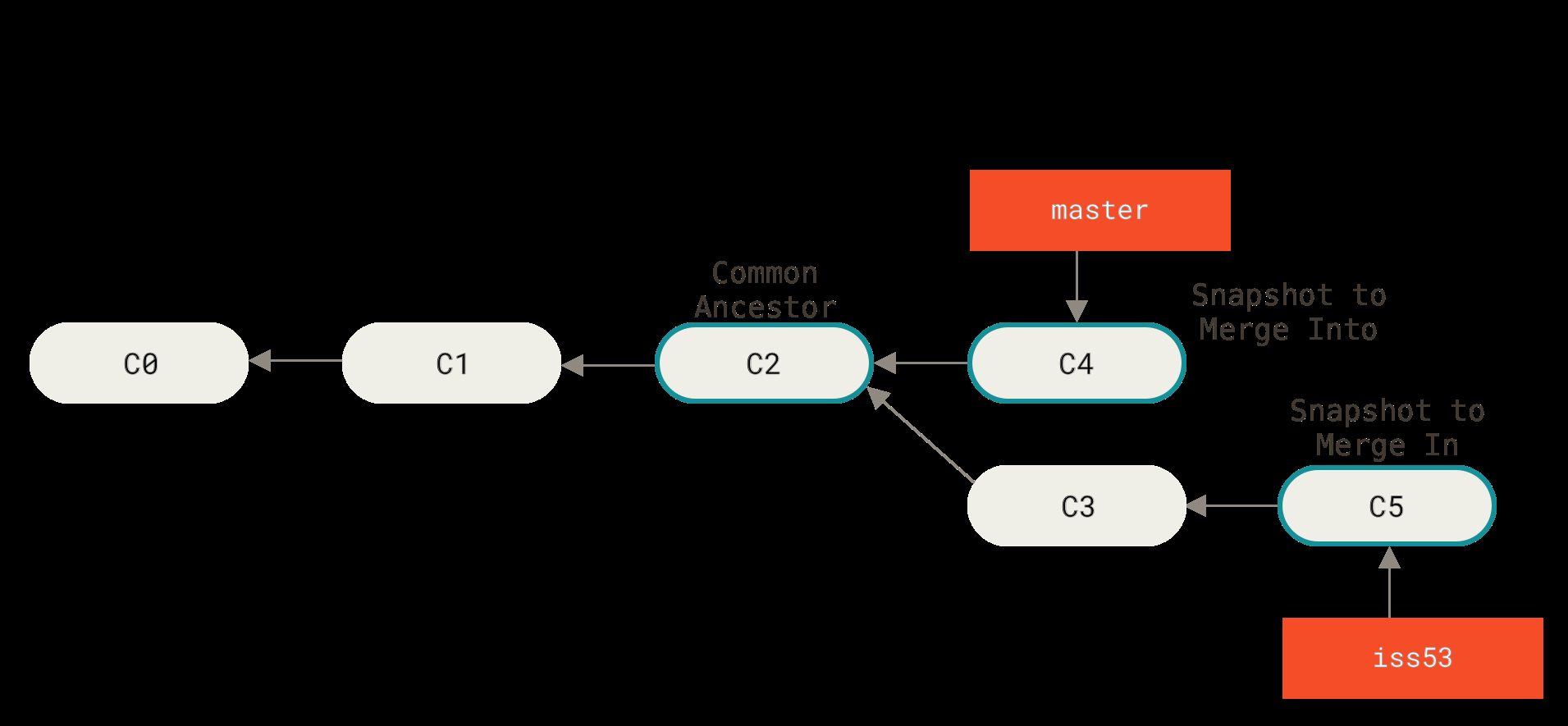
场景二:三方合并(Three-Way Merge)
回到正常开发。假设在 iss53 分支上做了几次提交,master 上也有新的提交,历史已经分叉。这时把 iss53 合并回 master:
1 | git checkout master |
因为两个分支的顶端不能直接线性到达对方,Git 会做一次三方合并——取三个快照:两个分支的最新提交 + 它们的共同祖先:
合并的结果是一个合并提交,它有两个父 commit:
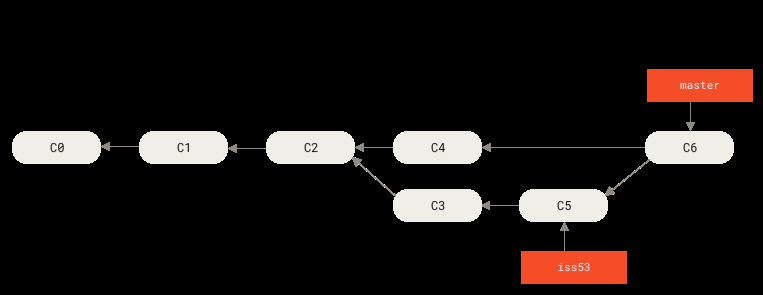
合并完成后,iss53 上的工作已经全部包含在 master 里,可以删掉了:
1 | git branch -d iss53 |
git branch -d只会在分支已合并的前提下删除。如果分支还有未合并的工作,Git 会拒绝删除并提示你用-D强行删除(注意这会丢失提交)。
合并冲突
如果两个分支改了同一个文件的同一部分,Git 无法自动合并,会停下来等你解决:
1 | <<<<<<< HEAD:index.html |
手动编辑成想要的版本后,git add 标记为已解决,再 git commit 完成合并。
Rebase:另一种整合分支的方式
除了 git merge,Git 还提供了另一条整合分支的路径——rebase(变基)。
假设历史已经分叉:
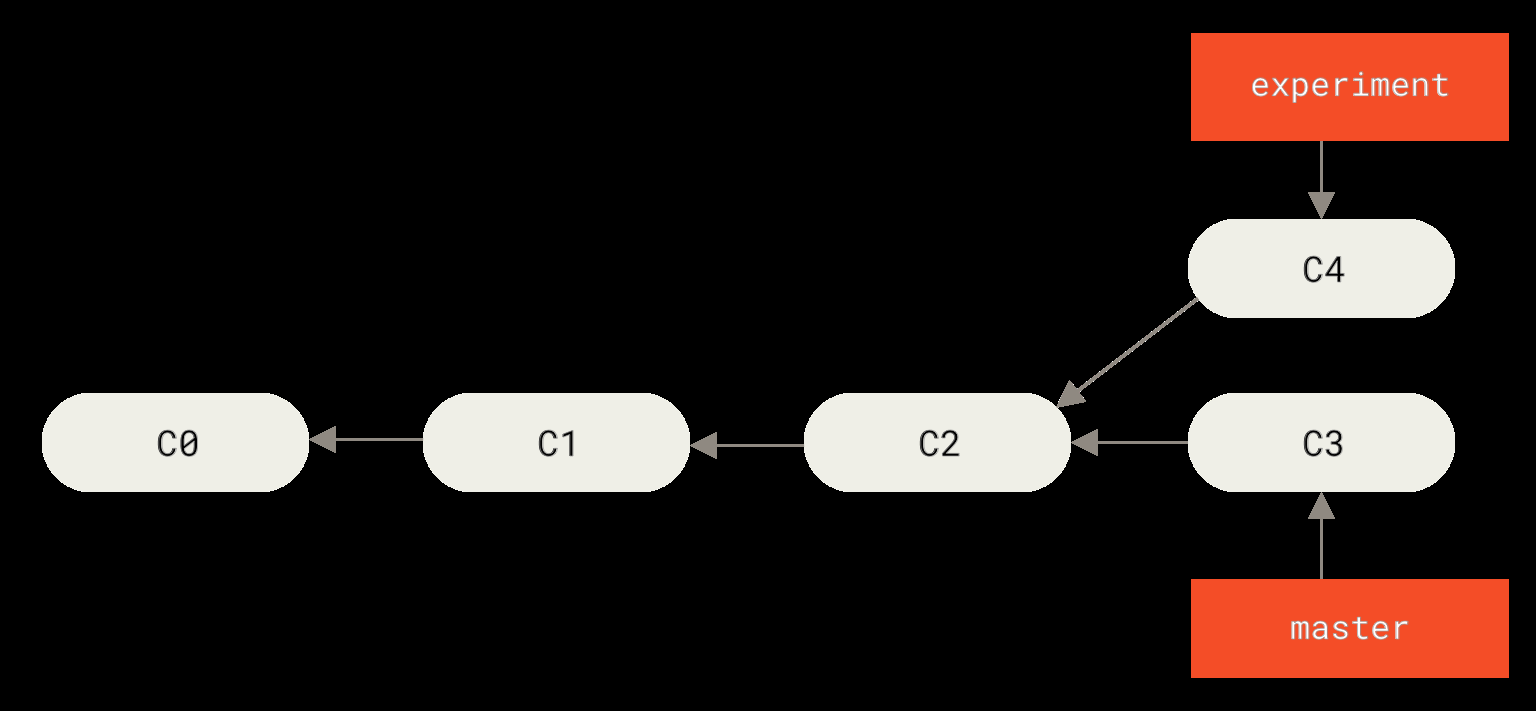
用 merge 是做一个三方合并,生成一个合并提交:

而 rebase 的做法是:把你分支上的每一次变更”摘下来”,按顺序在目标分支的顶端重新应用:
1 | git checkout experiment |

rebase 的原理是:找到两个分支的共同祖先,把当前分支相对于共同祖先的每一个变更保存成临时文件,然后把当前分支重置到目标分支的最新 commit,再逐一应用这些变更。
rebase 完成后,experiment 分支的基底变成了 master 的最新提交,历史变成了一条直线。此时再切回 master 做合并,就变成一个简单的快进合并了:
1 | git checkout master |

merge vs rebase 怎么选
两种方式最终得到的目录快照是一样的,区别在于历史记录:
- merge 保留真实的分叉历史,能看到”什么时间并行开发了什么”
- rebase 让历史呈线性,看起来像串行开发的,更加整洁
一个常用的策略是:用 rebase 整理本地尚未推送的 commit,用 merge 合并已推送的分支。具体来说:
- 在推送到远程之前,用
git rebase -i整理自己的 commit(合并、重排、改消息) - 合入团队共享分支时用
git merge,保留协作痕迹
黄金法则:永不 rebase 已推送的 commit
不要 rebase 已经推送到远程仓库、且其他人可能基于它工作的 commit。
rebase 的本质是丢弃旧的 commit,创建内容相同但哈希值不同的新 commit。如果别人已经基于旧 commit 做了开发,你突然把旧 commit 换掉,对方再次拉取时就会陷入混乱。
1 | # ✅ 可以:rebase 自己本地还没 push 的 commit |
分支管理
1 | git branch # 列出所有分支(* 表示当前分支) |
远程分支
当你的项目托管在 GitHub/GitLab 上时,本地仓库和远程仓库之间的分支关系通过远程跟踪分支来维护。每次 git fetch 或 git pull 都会更新这些指针。推送本地分支到远程:
1 | git push origin <branch> |
删除远程分支:
1 | git push origin --delete <branch> |
3.2 Commit Message 规范
推荐 Conventional Commits 格式:
1 | <type>(<scope>): <description> |
feat— 新功能fix— 修复refactor— 重构(不修 bug 不加功能)docs— 文档style— 样式/格式(非 CSS)perf— 性能优化test— 测试chore— 构建/工具
示例:
1 | feat(login): add OAuth2 Google login |
几条硬性规定:
- 标题不超过 72 字符
- 用祈使句(”Add” 不是 “Added” 或 “Adds”)
- 关联 Issue:
Closes #123或Refs #456
3.3 PR 规范
标题: 跟 commit message 标题一样,简短明了。
描述模板:
1 | ## Summary |
PR 大小控制: 一个 PR 不要超过 400 行改动。超过的拆分成多个 PR。400 行是 review 的注意力极限。
3.4 Review 流程
提 PR 的一方:
- 自己先过一遍 diff,不要提交了就甩手
- PR 描述写清楚改动动机和测试方式
- 带上截图或录屏(UI 改动)
- 标注需要重点 Review 的文件
Review 的一方:
- 先理解上下文,再看具体代码
- 区分”必须改”和”建议改”
- 必须改: 逻辑错误、安全问题、性能隐患
- 建议改: 命名、风格、可读性提升(用
nit:前缀标注)
- 对事不对人,用疑问句代替命令句
- ❌ “这里写错了”
- ✅ “这里是不是应该处理
null的情况?”
- 如果 PR 太大,要求拆分而不是硬看
合入条件: 至少 1 人 Approve + CI 通过。
四、Git 进阶技巧
掌握了基础命令和协作规范之后,下面这些技巧能让你在实际场景中更游刃有余。
4.1 精细化暂存:git add -p
一个文件改了多处,但想分成多次 commit?git add -p 会把每个改动块逐一展示,让你决定是否暂存:
1 | git add -p |
每个 hunk 可以选:
y— 暂存n— 跳过s— 拆分成更小的 hunke— 手动编辑(精准选择要暂存的行)
4.2 临时保存现场:git stash
写到一半被叫去修紧急 bug?git stash 可以把当前工作区完整保存,回来再恢复:
1 | # 暂存并加备注 |
popvsapply:pop恢复后自动从 stash 列表删除;apply恢复但保留 stash,适合拿出来看看,不合适再换一个。
git clean — 清理 untracked 文件
和 git stash 配套的另一个命令。当你想要一个完全干净的工作目录时:
1 | # 列出会被删除的文件(先预览,安全操作) |
场景: 构建项目生成了大量临时文件,git clean -f -d 一键清理,回到干净状态。
4.3 查看历史与排查
git log 的进阶用法
1 | # 图形化查看所有分支的历史 |
git grep — 在 commit 历史中搜索代码
比 git log -S 更直接的搜索方式。直接在工作区或任意 commit 中搜索代码:
1 | # 在工作区搜索 |
git diff
查看工作区与暂存区的差别、或者两个分支之间的差异:
1 | # 工作区 vs 暂存区 |
git blame — 找上下文
不是用来甩锅的,是用来找上下文的:
1 | # 看每行谁改的、什么时候改的 |
git bisect — 二分查找 bug
知道功能之前是好的、现在坏了,但不知道哪个 commit 引入的 bug:
1 | git bisect start |
也可以自动化:
1 | git bisect start HEAD v1.0 |
4.4 改写历史
git rebase -i — 交互式变基
整理 commit 历史的利器。可以把多个小 commit 合并成一个,或者修改 commit message:
1 | git rebase -i HEAD~3 # 修改最近 3 个 commit |
| 命令 | 作用 |
|---|---|
pick |
保留 |
reword |
只改 commit message |
squash |
合并到上一个 commit |
fixup |
合并但丢弃 message |
drop |
删除整个 commit |
黄金法则: 只 rebase 尚未推送 的 commit。
git revert — 安全撤销已推送的 commit
对于已经推送到远程的 commit,不要用 reset,要用 revert:
1 | # 创建一个新 commit 来抵消目标 commit 的改动 |
revert 和 reset 的核心区别:
| 命令 | 效果 | 适用场景 |
|---|---|---|
git revert HEAD |
创建新 commit 抵消目标 commit | 撤销已推送的 commit(安全) |
git reset --soft/mixed/hard |
移动 HEAD 指针,可能改写历史 | 撤销未推送的本地 commit |
原则: 已推送的用 revert,未推送的用 reset。关于 reset --soft/mixed/hard 的详细用法,见第二章的”撤销与回退”。
4.5 后悔与挽救
git reflog — 本地操作日志
git reflog 记录了所有 Git 操作的历史,包括被删除的 commit。如果你 git reset --hard 删过头了,可以从 reflog 找回:
1 | git reflog |
输出:
1 | abc1234 HEAD@{0}: commit: fix login bug |
找回:
1 | git reset --hard ghi9012 |
注意: reflog 是本地的,不会同步到远程,默认 90 天后过期。
git cherry-pick — 精准取 commit
从其他分支挑一个 commit 应用到当前分支:
1 | git cherry-pick <commit-hash> |
场景: 在 dev 分支修复了一个 bug,hotfix 分支也需要同样的修复。不用合并整个分支,cherry-pick 那一个 commit 就行。
4.6 多分支并行:git worktree
不用反复 git stash + git switch,可以在不同目录同时维护多个分支:
1 | # 在 ../hotfix 目录 checkout 一个 hotfix 分支 |
场景: 当前分支开发到一半,需要切到其他分支改个紧急问题。不用 stash,直接 git worktree add,在另一个目录改完 push 回来继续。
五、Git LFS:大文件管理
为什么要用 Git LFS
Git 擅长管理文本文件(代码),但不擅长管理大文件(图片、视频、模型文件、编译产物)。直接把大文件提交到 Git 仓库会导致:
- 仓库体积暴涨,
git clone越来越慢 - 每次修改大文件,Git 都要存一份完整副本(不是差异)
.git目录越来越大
Git LFS(Large File Storage) 的解决思路:把大文件的内容替换成一个指针文件,真正的文件内容存储在远程 LFS 服务器上。
1 | Git 仓库中的文件 LFS 服务器上的文件 |
克隆仓库时只下载指针文件,真正的大文件按需下载。
安装与配置
1 | # 安装 LFS(需要先装 Git) |
使用方式
1 | # 在仓库中指定哪些文件类型由 LFS 管理 |
常用命令
1 | # 查看当前 LFS 跟踪规则 |
注意事项
- LFS 有存储配额限制(GitHub 免费套餐 1GB 存储 + 每月 1GB 流量)
- 已提交的大文件不会自动变小 — 需要用
git lfs migrate重写历史 - 服务器端也需要支持 LFS(GitHub、GitLab、Gitee 都支持)
- 团队成员都要安装
git lfs install,否则 clone 下来的是指针文件而不是真实内容